Cyber Security Courses and Services
 Certification Courses
Certification Courses
IEMLabs offer Certification Courses in different trending courses under the domains of Cyber Security, Networking. Programming Language etc. The experts offering the courses are working and have several years of working experience This helps to build more confidence to get a thorough grip of the courses
 Software and Development
Software and Development
IEMLabs is best known for its innovative softwares that helps students and other professionals to make their work easy.Our software developers provide expert application development services to our clients.We are in constant growth by developing products like IEMSecure and many more.
 ISMS/VAPT Audit
ISMS/VAPT Audit
IEMLabs offers VAPT audits which are essential tools for ensuring the security of any organisation's IT infrastructure Vulnerability assessments help to identify potential security weaknesses, while pen testing simulates real-world attacks to determine how well a system can withstand a malicious attack
 ISO Audit
ISO Audit
IEMLabs offers Consultation & Implementation of ISO (International Organization for Standardization) 9001, ISO 27001 ISO 27701 to GDPR ISO 9001 targets compliance offers a logical and feasible app QMS (Quality Management System) to track all domains of a particular business & ISO 27001 focuses on Information Security
About Us
IEMLabs, a unit of IEMA Research & Development Pvt. Ltd. is an ISO 27001:2013 and ISO 9001:2015 certified company. The company was founded in 2016 by Mr. Satyajit Chakrabarti with the primary purpose of developing software. Later he teamed up with Mr. Sovik Sinha Chowdhury, BTech Graduate to expand the mission with compliance service, corporate training, VAPT, and ISO-Audit. The company has a strong focus on helping small businesses and organizations improve their cyber security posture. With years of experience working with governments, law enforcement organizations, and businesses, IEMLabs Pvt. Ltd. offers IT security training. Over the years, we have seen a lack of skilled workers in the IT security sector. This institution aims to teach senior working professionals as well as new engineers in-depth knowledge of IT security.
Trending Courses
IEMLabs offers courses that help you get ready for industry demanding skills and become job ready.









Upcoming Batch Schedule
-
Diploma in Cyber Security
Cybercrimes are also getting more and more common in our daily lives as information technology advances globally. Companies are working with cybersecurity professionals to make their infrastructure more secure in an effort to avoid this. As a result, cyber security is becoming more and more significant in today's environment.This Diploma Course in Cyber Security | DCS from IEMLabs is offered to you as a result. You'll know everything there is to know about Python programming, networking, web development, ethical hacking, network penetration testing, and web application penetration testing at the end of this course.
Time : All Days (10am-7pm)
Batch 1
Schedule Date : 2024-03-10
Duration : 2 hours
Batch 2
Schedule Date : 2024-03-25
Duration : 2 hours

-
Certified Ethical Hacker C|EH v12
This certified ethical hacking course of EC Council has much value to offer the students since IEM Labs, Kolkata always focuses on giving the best possible industry exposure to the students through all the practical classes and projects during the whole curriculum of the training program. Being an Ethical Hacker/Cyber Security Analyst, the student can get jobs in many prestigious MNCs and helps to identify all the vulnerabilities in the network infrastructure and to resolve them.
Time : All Days (10am-7pm)
Batch 1
Schedule Date : 2024-03-10
Duration : 2 hours
Batch 2
Schedule Date : 2024-03-25
Duration : 2 hours
-
Certified Full-Stack Web Developer
A web developer who works on both the front end and back end of a website is known as a full stack developer. There is a huge need for Full Stack Web Developers in many of the international corporations that we encounter. Any company's website can be thought of as its public face, so it is up to the developer to create a website that is optimized. The students in this web development course will learn the principles of web development from scratch, giving them a qualitative understanding and competitive advantage to work on these areas in the real world. Students will be able to develop both the front end and the back end of any fully functional website by the end of this course. Industry experts with years of experience in this subject will provide the training.
Time : All Days (10am-7pm)
Batch 1
Schedule Date : 2024-03-10
Duration : 2 hours
Batch 2
Schedule Date : 2024-03-25
Duration : 2 hours
-
Android Application Developer with data structure Training
Android Application Development is the most common application of the Java Programming Language. An Android developer can get rewarding pay packages from companies that develop Android Applications. This is why IEMLabs brings you this US-based summer/winter training program wherein you will be taught about the basics of Android Applications, how they work and how to develop them.
Time : All Days (10 A.M.-7 P.M.)
Batch 1
Schedule Date : 2024-03-10
Duration : 2 hours
Batch 2
Schedule Date : 2024-03-25
Duration : 2 hours
-
CCNA Routing and Switching Courses
CCNA Routing and Switching Courses at IEMLabs are designed to provide students with the skills and knowledge necessary to configure, troubleshoot, and maintain networks using Cisco certified devices. These courses cover network fundamentals, IP addressing, routing protocols, switching technologies, security, and automation. By completing these courses, students can take the CCNA certification exam and demonstrate their proficiency in networking concepts and practices. IEMLabs offers online and offline learning modes, flexible timing, and experienced instructors. Students will also get access to live virtual labs to practice their skills on actual Cisco equipment. Whether you are a beginner or an intermediate-level network professional, the CCNA Routing and Switching Courses at IEMLabs will help you advance your career and achieve your goals.
Time : All Days (10 A.M.-7P.M.)
Batch 1
Schedule Date : 2024-03-10
Duration : 2 hours
Batch 2
Schedule Date : 2024-03-25
Duration : 2 hours
What Our Students Say
-

“As a Network and Cyber Security Engineer at International Combustion (India) Limited, I enrolled in IEMLabs CEHv12 Program for 40 hours in 2024. I am now certified EC Council's Ethical hacker. I owe all the credits to IEMlabs and its faculty for this wonderful training and made me score high.”

Shuvam HarChaudhury
Network and Cyber Security Engineer -
“IEMLabs gives cybersecurity students a significant advantage. The teachers are also very kind to the students and create a pleasant environment for them.”

Soumodeep Guha
Student -
“I signed up for an IEMLabs Kotlin app development course. The course had been meticulously constructed. Anubhab Sir was a fantastic teacher.”

Sucharita Das
Student -
“I am pleased to share that the training and expertise I got from IEMLabs immensely helped me learn CCNA and get placed as a network support Engineer at Sky Tech.”

Supriyo Mondol
Sky Tech, Network Support Engineer -
“It's an excellent place to learn about network security. The NPT course has proven to be really valuable. I am a college student, and it has greatly benefited me in developing this new skill and applying it to a variety of activities.”

Puja Saxena
Student -
“Being placed at Wishnet as a network expert, I would like to thank IEMlabs for making my learning successful. I learned how to maintain network devices and systems through the Ec Council’s CCNP Course.”

Palashtaru Dutta
Wishnet, Network Support Engineer -
“Throughout my Machine Learning with Python direction session, I had a incredible mastering experience. IEMLabs' school is most of the best, and that they train the whole lot from the floor up.”

Jasveer Singh
Student -
“I am very happy to share my experience of completing the CEH course at IEMlabs. I have learned many practical skills and techniques for ethical hacking and penetration testing.”

Rohan Das
CEH Certified -
“I learned a lot about ethical hacking, vulnerabilities, and penetration testing from day one. All of this was due to the support of the excellent teachers at IEMLabs. The learning environment at IEMLabs is excellent and all the instructors are warm and welcoming.”

Vishwajeet Shivankar
Student -
“The trainers were very knowledgeable and helpful, and IEMLabs were well-equipped with real-time cyber experts.”

Aindrila Das
CEH Certified -
“It offers an excellent environment for academic progress as well as the acquisition of new skills and technology. I completed my JAVA training. It seemed far too good to be true. I plan to take the PYTHON class. I wholeheartedly recommend it.”

Kavita Pareek
Student -
“I had a great time studying at IEMLabs. All teachers are very competent and experienced in this area. The teachers have been and are a great help to me throughout the process. I recommend everyone to participate in IEMLabs.”

Pinky Singh
Student -
“I have enrolled in the CEH course at IEMLabs with no cybersecurity knowledge and have now successfully earned the CEH certification of the EC Council.”

Samrat Chakraborty
CEH Certified -
“One of the best cybersecurity training colleges. I would advise any student interested in taking a course at IEMLabs to do so.”

Ganesh Lokhande
Student -
“I got the opportunity to work on real-world projects and challenges, which boosted my confidence and prepared us for the CEH certification exam.”

Subhadeep Karmakar
CEH Certified -
“I am thankful to IEMLabs to provide an enjoyable journey for me in gaining certification on EC Council’s latest version CEHv12 with flying colors.”

Partha Pratim Khanra
CEH Certified

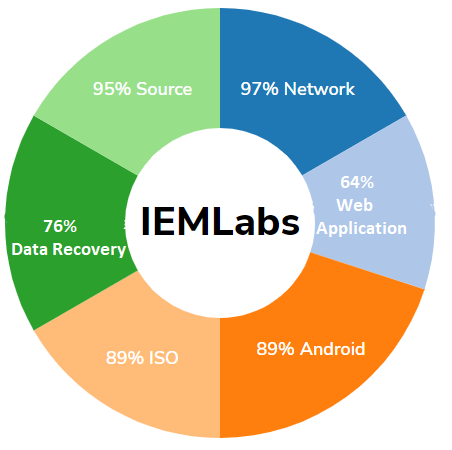
Compliance & Security Audits
- Network Vulnerability Assessment And Penetration Testing N | VAPT
- Web Application Vulnerability Assessment & Penetration Testing W | VAPT
- Android Vulnerability Assessment And Penetration Testing A | VAPT
- iOS Vulnerability Assessment And Penetration Testing I | VAPT
- Data Recovery Services
- Source Code Review | SCR
24/7 Security Operations Centre
You can secure your infrastructure with the help of our Security Operations Center by tracking and countering the incoming attacks Live.

Our Clients
Who We Work With




























OUR PARTNERS
Who We Have Integrated With


OUR CLIENT'S OPINION
Testimonials
-

Debjit Mookherjee
-

Mayank Bachhawat
-

Vikram Newar
-

Vedansh
Latest News From Blogs











 About Us
About Us







